



该文章只讲述了cache lab的第一部分,第二部分由于技巧性过于强,所以没做..
基础知识
由于cpu寄存器与内存的速度差异越来越大,产生了在寄存器与内存之间的l1/l2/..等缓存,在执行命令时,涉及内存操作的首先会去缓存中查找相应的数据是否存在,如果存在,则直接从缓存中读写数据,否则,才会去内存进行读写操作。
缓存需要解决的一个问题是,对于任意一个内存地址,要如何判断其是否在缓存中,如果在,如何获取对应地址的数据。
缓存的结构如下图所示,cache包含S个set,每个set中,包含E个lines,而每个lines中,包含一位的valid bit、t位的tag bits和 B = 2^b bytes的数据块。刨除valid bit和tag bits,该cache中可以存储 S * E * B bytes的数据。
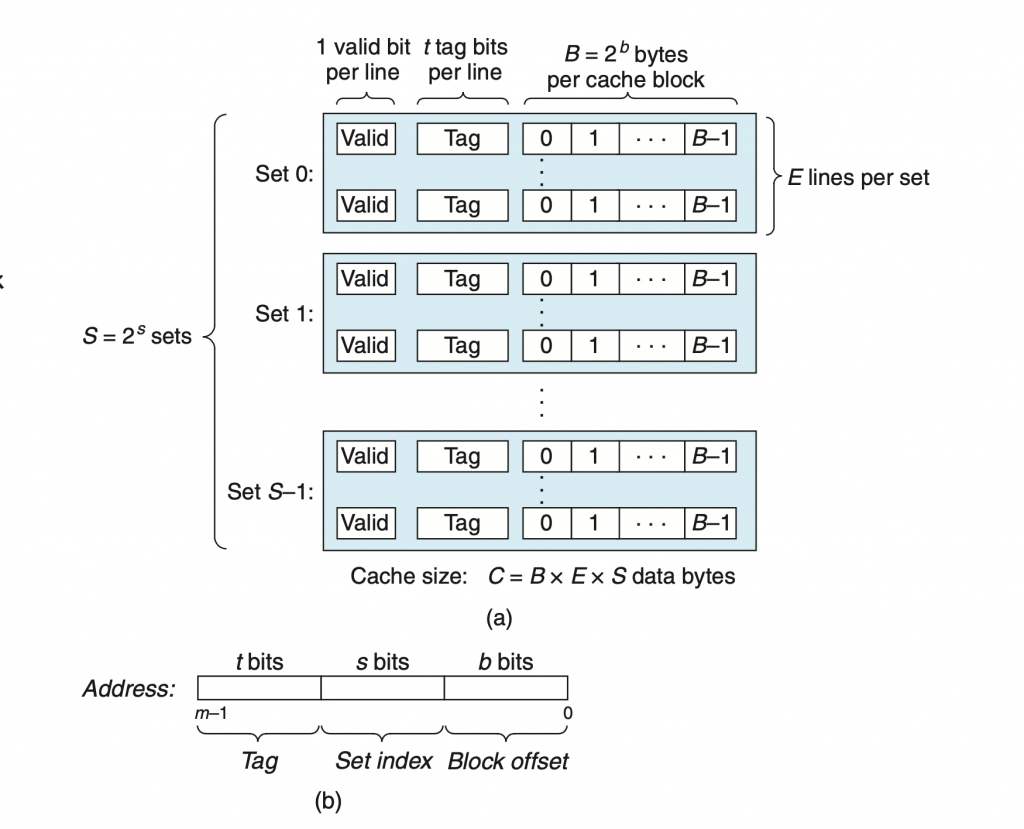
在缓存的设计中,由b图可以看到,m位的地址被分为t bits的tag、s bits的set index以及b bits的block内偏移。具体来说,就是对于任意一个m位的地址,首先先取中间的s位,计算出set的index S=2^s,来确认该地址的数据会被存储在哪一个set中,再去查找该set中有哪个line的tag是和该地址的tag一致,如果找到了某个line,其tag与地址的tag一致,且该line的valid bit为true,则该地址所存储的数据在该line中,找到该line后,通过地址的最低b位的数据,找到所要获取数据在该line的offset,之后读取该数据即可。
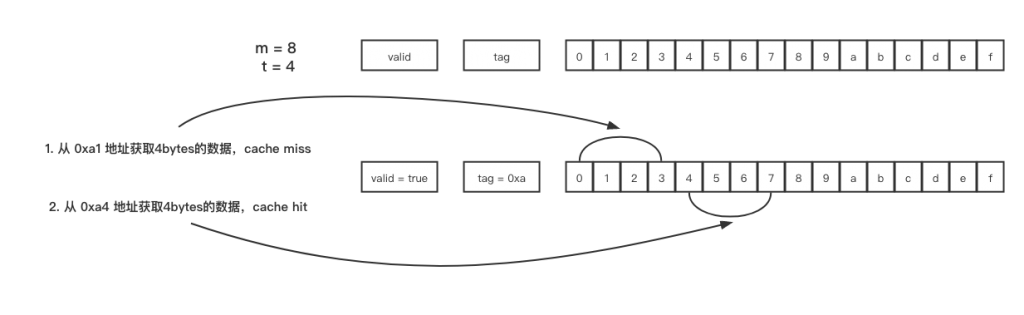
当s=0时,可以看到该m位的地址被分为t位的tag段和b位的block offset段,并且缓存中仅有一个set,这种情况被称为Fully Associative Caches。该方式也更为直观:以m=8,t=4举例,对于地址0xa1来说,tag=0xa,存储了2^4 = 16 bytes的数据,也就是说,地址0xa0-0xaf的数据都被存储在tag=0xa的line中,如果下次需要从0xa4地址中,取4个bytes的数据,则直接可以在tag=0xa的line中,从offset=4往后取4个bytes即可。
当s不为0时,区别仅仅在于在查询tag之前,先用中间的s位去确认数据应该在第几个set,然后再通过tag来进行查询。
这里有个问题是,为什么最高几位表征tag,而中间几位是表征set index呢?如果反过来,高几位为set index,中间位是tag会有什么结果?考虑连续访问数组的情况,如果用最高位作为set index,在顺序遍历数组时,最高位往往保持不变,也就意味着数组中的元素都会被缓存到同一个set的不同line中,这也就造成了当set中的line的数量较小(也就是E比较小时),会造成频繁的cache逐出的情况,使得cache miss的情况增多;而如果使用中间几位作为set index,顺序遍历数组时,不同的数组块就会被映射到不同的set中,也就意味着能缓存的数组数据量变大了。
cache lab
cache lab的地址:http://csapp.cs.cmu.edu/2e/cachelab.pdf
第一部分就是实现一个脚本,输入是s/E/b的大小以及一个内存操作文件,输出为在给定的cache规格的条件下,该内存操作命中/miss/逐出了多少次缓存操作。内存操作文件每行的格式为operation address,size,operation指代操作类型,有M(modify)、L(load)、S(save)三种,address为内存的地址,size为需要操作的操作数长度。
整体的实现较为简单,首先对于输入的s和t创建相应大小的数据结构,数据结构如下图所示,整体的cache由sets[]组成,每个元素包含set的序号和对应的line的数组,每个line用setvalue来表示,其中,validbits代表是否有效,ts类似时间戳,用来做逐出用。
struct setvalue {
int validbits;
int tag;
int ts;
};
struct sets {
int setno;
struct setvalue *values;
};在读取内存操作文件中的数据时,对于每个地址,先计算出来该地址对应的缓存的set序号以及tag,计算逻辑如下:通过位运算计算出对应的smask和tmask,与地址做&操作后进行移位,即可获得set的序号和tag的大小。
const int bmask = (1<<b) - 1;
const int smask = (1<<(s+b)) - bmask - 1;
const unsigned long tmask = ~0 - smask - bmask;
soffset = (address & smask) >> b;
tnum = (address & tmask) >> (b+s);计算出后,去sets数组中找到对应的set,再遍历line中是否有tag与计算出来的tag相等,如果相等且validbits为1,则证明cache中包含该地址存储的值,否则,进行load的操作。
整体代码如下:
#include "cachelab.h"
#include <getopt.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
const int hitResultMask1 = 0x1;
const int hitResultMask2 = 0x10;
const int missResultMask = 0x100;
const int evictResultMask = 0x1000;
struct setvalue {
int validbits;
int tag;
int ts;
};
struct sets {
int setno;
struct setvalue *values;
};
int getaddr(char *);
int process(char itype, struct sets *ss, int e, int soffset, int tnum, int* tscounter) {
struct sets theset = ss[soffset];
int i;
int cacheresult = 0;
for (i = 0; i < e; i++) {
if (theset.values[i].validbits == 1 && theset.values[i].tag == tnum) {
theset.values[i].ts = *tscounter;
*tscounter += 1;
cacheresult |= hitResultMask1;
if (itype == 'M') {
cacheresult |= hitResultMask2;
}
return cacheresult;
}
}
int evictIndex = 0;
for (i = 0; i < e; i++) {
if (theset.values[i].validbits != 1) {
evictIndex = i;
break;
} else if (theset.values[i].ts < theset.values[evictIndex].ts) {
evictIndex = i;
}
}
cacheresult |= missResultMask;
if (theset.values[evictIndex].validbits == 1) {
cacheresult |= evictResultMask;
}
theset.values[evictIndex].validbits = 1;
theset.values[evictIndex].tag = tnum;
theset.values[evictIndex].ts = *tscounter;
*tscounter += 1;
if (itype == 'M') {
cacheresult |= hitResultMask2;
}
return cacheresult;
}
int main(int argc, char *argv[])
{
int isverbose = 0;
int opt = 0;
int s = 0, e = 0, b = 0;
int tscounter= 0;
char *tpath;
// parse arguments
while ((opt = getopt(argc, argv, "hvs:E:b:t:")) != -1) {
switch (opt) {
case 'h':
break;
case 'v':
isverbose = 1;
break;
case 's':
s = atoi(optarg);
break;
case 'E':
e = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
tpath = optarg;
break;
}
}
printf("%d %d %d %d %s\n", isverbose, s, e, b, tpath);
// init sets
int setsize = 1 << s;
struct sets *ss = malloc(setsize * sizeof(struct sets));
int i, j;
for (i = 0; i < setsize; i++) {
ss[i].setno = i;
ss[i].values = malloc(e * sizeof(struct setvalue));
for (j = 0; j < e; j++) {
ss[i].values[j].validbits = 0;
ss[i].values[j].tag = 0;
ss[i].values[j].ts = 0;
}
}
FILE *fp;
fp = fopen(tpath, "r");
if (fp == NULL) {
exit(EXIT_FAILURE);
}
int hitsresult = 0, missresult = 0, evictresult = 0;
const size_t line_size = 300;
char* line = malloc(line_size);
// int boffset = 0;
int soffset = 0, tnum = 0;
const int bmask = (1<<b) - 1;
const int smask = (1<<(s+b)) - bmask - 1;
const unsigned long tmask = ~0 - smask - bmask;
while (fgets(line, line_size, fp) != NULL) {
int size = strlen(line);
if (size > 1 && line[0] == ' ') {
char itype = line[1];
int address = getaddr(line);
soffset = (address & smask) >> b;
tnum = (address & tmask) >> (b+s);
int result = process(itype, ss, e, soffset, tnum, &tscounter);
// parse result
if (isverbose == 1) {
line[size-1] = '\0';
char* lr = line + 1;
printf(lr);
}
if ((result & missResultMask) != 0) {
missresult += 1;
if (isverbose == 1) {
printf(" miss");
}
}
if ((result & evictResultMask) != 0) {
evictresult += 1;
if (isverbose == 1) {
printf(" eviction");
}
}
if ((result & hitResultMask1) != 0) {
hitsresult += 1;
if (isverbose == 1) {
printf(" hit");
}
}
if ((result & hitResultMask2) != 0) {
hitsresult += 1;
if (isverbose == 1) {
printf(" hit");
}
}
if (isverbose == 1) {
printf("\n");
}
}
}
fclose(fp);
if (line) {
free(line);
}
for (i = 0; i < setsize; i++) {
free(ss[i].values);
}
free(ss);
printSummary(hitsresult, missresult, evictresult);
return 0;
}
int getaddr(char *line) {
int i;
char *r = malloc(strlen(line) + 1);
char *tmp = r;
for (i = 3; i < strlen(line); i++) {
if (line[i] == ',') {
break;
}
*tmp = line[i];
tmp++;
}
*tmp = '\0';
return (int)strtol(r, NULL, 16);
}
Comments | NOTHING